Reinforcement Learning Introduction

The first time I heard about Reinforcement Learning (RL) was at an orientation meeting a few years ago. Back then, I barely understood it, especially while listening to others ask questions. Only recently have I come to understand it a bit more, and reflecting on this journey feels like my own RL story—with an extremely long trajectory that has led me to where I am now. Even though we don't have a truly optimized policy to guide us in life, it still feels like we're constantly trying to learn one as we go.
Anyway, let's talk about RL.
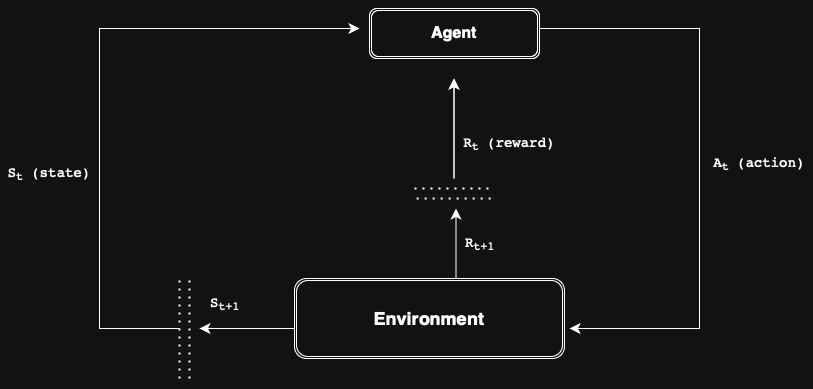
There are several components in RL as followed:
- State: situation that an agent can observes.
- Agent: decision-maker that interacts with the environment.
- Action: possible decisions an agent can make.
- Reward: feedback signals received via environment.
- Environment: everything outside the agent that it interacts with.
Thinking about learning how to play Rubik's Cube. The corresponding components to form a RL system is depicted as below:
- State: current pattern of colors on all faces of the cube.
- Agent: the player who tries to solve it.
- Action: rotations of each face you can make such as front face clockwise 90, 180, 270 degrees, and etc. This typically includes 6 faces * 3 rotation possible moves.
- Reward
- Positive Reward: a large positive scalar value when cube is solved.
- Negative Reward: small penalty to encourage efficient solutions. Complex reward shaping is possible to deduce better model.
- Sparse Reward: no reward until final state is reached.
- Shaped Reward: intermediate rewards based on partial progress.
- Environment: Rubik's cube itself.
Apparently, the target (ideal) state is when all faces of the cube have the same color. This raises the question: how does RL process apply here?
In fact, it's quite similar to how humans learn to solve the cube — the main difference lies in how the agent perceives the cube. Instead of visually seeing the colors, the RL agent represents the cube's state numerically. However, this is essentially the same approach we might take if we were to label each color with numbers and track their positions — converting a visual puzzle into a structured, logical format that can be understood and manipulated algorithmically.
Conclusion
This is the introduction to the basics of RL. In the following posts, we’ll begin to explore the core concepts in greater depth, unraveling its intricate components to see how RL can be applied to real-world problems.



